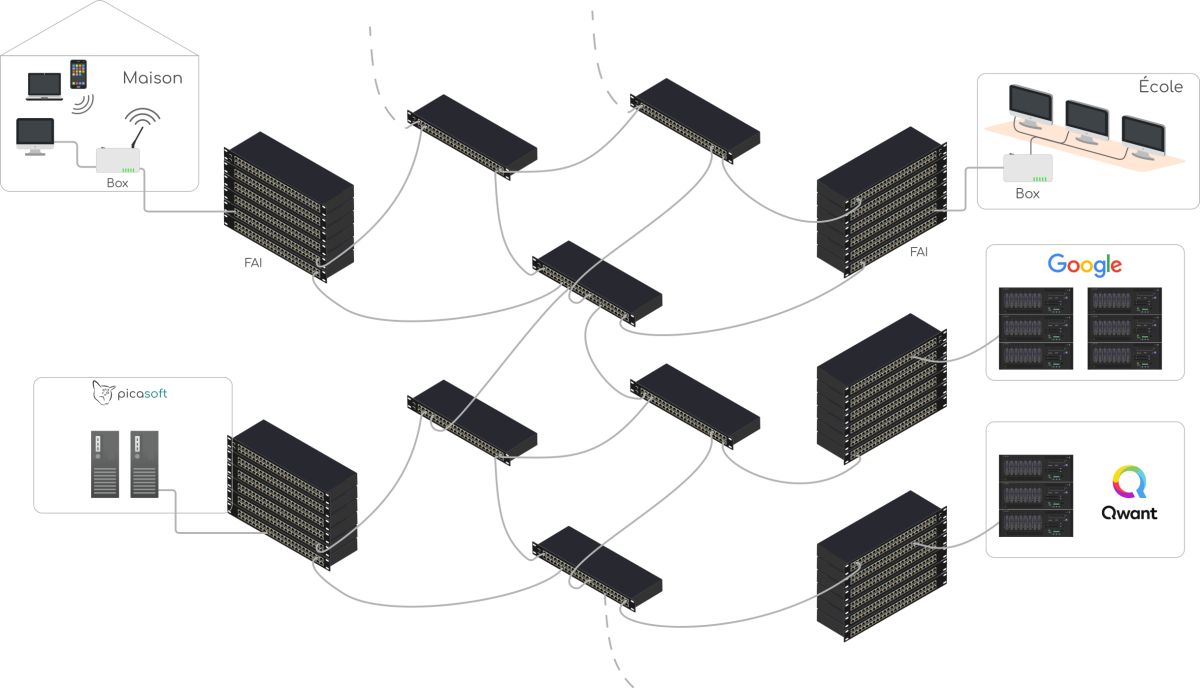
Principe de la communication sur Internet
Une communication via Internet implique :
les ordinateurs des personnes qui communiquent, on les appelle des clients ;
les routeurs, ce sont des ordinateurs dont le rôle et de faire passer l'information d'un ordinateur à un autre sur Internet ;
en général des serveurs, ce sont des ordinateurs en charge de gérer la communication pour un ensemble de clients ;
des moyens physiques pour relier ces ordinateurs (câbles et ondes) ;
des protocoles qui permettent à des logiciels installés sur ces machines de communiquer les unes avec les autres.
Fondamental : Internet est un vaste réseau d'ordinateurs qui communiquent entre eux
Pour que les clients, les routeurs et les serveurs puissent communiquer entre eux, ils faut qu'ils soient reliés physiquement et qu'ils hébergent des logiciels qui respectent des protocoles communs.
Exemple :
Complément : Des machines et des logiciels (confusing !)
Les termes de serveur et de client sont utilisés pour des machines, mais également pour des logiciels.
Ainsi Apache est un serveur web, c'est à dire un logiciel destiné à tourner sur une machine serveur et donc à répondre à des requêtes HTTP, tandis que Firefox est un client web, c'est à dire un logiciel destiné à tourner sur une machine cliente et donc à envoyer des requêtes HTTP.
Complément : Des clients qui sont aussi des serveurs...
Il est possible qu'une machine soit à la fois un client et un serveur :
Si vous avez un ordinateur chez vous, vous pouvez tout à fait héberger un serveur web (qui est accessible quand la machine est allumée et connectée à Internet) et vous pouvez aussi vous en servir comme ordinateur personnel (donc par exemple pour consulter des sites web).
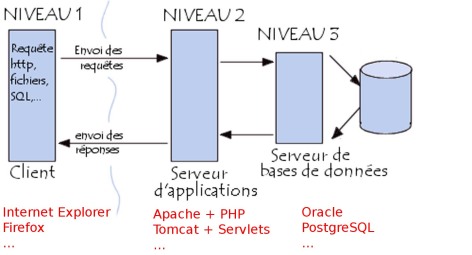
Dans les architectures à plusieurs couches (architectures n-tiers) un ordinateur peut à la fois répondre à des requêtes et en formuler : il est ainsi courant qu'un serveur web ait besoin de demander des informations à un serveur de base de données, dans ce cas la machine est serveur du point de vue du navigateur qui lui demande une page web et client du point de vue de la base de données à laquelle il demande les informations (qui vont lui permettre de créer la page web à renvoyer au client).