Des données brutes à la prédiction
Données et information
Définition : Information
Ici, on entend une information comme une prédiction réalisée à partir d'un grand nombre de points de données bruts.
Remarque : Émergence
On peut considérer une information comme une propriété émergente, c'est-à-dire une entité qui est plus que la somme de ses parties. C'est l'utilisation de modèles statistiques entraînés sur d'immenses quantités de données (machine learning) qui permet de faire émerger quelque chose de nouveau.
Prédictions de traits psychologiques
Exemple : Remplacer les évaluations psychologique ?
En 2019, un papier compile des études sur la prédictions des caractéristiques suivantes : émotions, bien-être, QI, qualité d'écriture, aisance verbale, valeurs morales, orientation sexuelle, orientation politique, appréciations des marques, traits OCEAN ( Nettle, 2009[1]), curiosité, autisme, dépression, dyslexie, psychopathie et stress.
Les technologies actuelles peuvent déjà déduire des informations probabilistes sur nos états mentaux et nos traits psychologiques et nous classer d'une manière qui dépasse les formes traditionnelles d'évaluation psychologique. […] À mesure que les types et la quantité d'interactions entre nous et nos appareils en ligne augmentent et que de nouveaux types de capteurs pour mesurer les signaux comportementaux sont développés, on s'attend à ce qu'en combinant ces sources d'information, un algorithme de Machine Learning (ML) puisse former une image très précise de nous. ( Burr et Cristianini, 2019[2]).
Exemple : Des signaux faibles à l'information
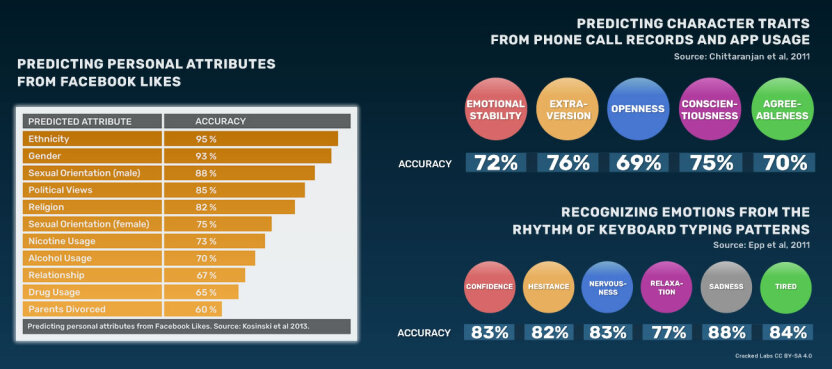
Toutes les prédictions ne se valent pas
Attention : Exactitude
La presse a tendance à surévaluer l'exactitude des prédictions algorithmiques. En 2012, le New York Times publiait un article influent, encore cité aujourd'hui. Il entendait notamment montrer comment un supermarché avait prédit la grossesse d'une jeune fille avant qu'elle ne le sache elle-même ( Duhigg, 2012[3]).
Pour autant, il omettait les notions d'exactitude, faux-positifs, faux-négatifs, précision, mémoire des données d'entraînement ( Fraser, 2020[4]).
Remarque :
La capacité de prédiction des algorithmes à base de machine learning est sujet à une hype massive, tant dans la littérature que dans l'opinion publique.
Pour autant, nombre de ces algorithmes performent extrêmement mal dans certaines situations.
Fondamental : Les prédictions sociales sont profondément dysfonctionnelles
Dans une étude co-écrites par 112 chercheur·ses, plus de 400 équipes spécialisées en machine learning ont tenté de prédire le devenir social de familles fragiles à partir de données collectées par les chercheur·ses pendant 15 ans ( Salganik et al., 2020[5]).
À partir de 13.000 variables (à 9 ans), l'idée était de prédire 6 variables (à 15 ans).
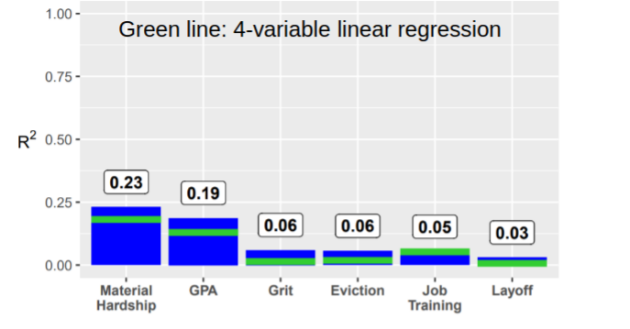
Les modèles en jeu sont issus de dizaines d'années de recherche et vendus par des entreprises avec des promesses particulièrement hautes.
Remarque : Les prédictions comportementales manquent d'évaluations
Certains alertent sur la possible sur-confiance donnée dans les prédictions comportementales des publicitaires.

Et si la publicité personnalisée promue par les géants du web n'était qu'un mirage ? Tim Hwang déconstruit le mythe promis aux annonceurs d'un accès sur mesure à chaque utilisateur ou utilisatrice de l'internet. Il dévoile, ce faisant, les pratiques spéculatives et les manipulations des grandes places de marché publicitaires, intimement liées aux monopoles du web.
Attention : Politiques publiques et prédictions algorithmiques
En général, les tribunaux utilisent ces systèmes pour évaluer la probabilité de récidive ou de fuite des personnes en attente de jugement ou des délinquants dans le cadre des procédures de libération sous caution et de libération conditionnelle. Par exemple, l'algorithme bien connu de la Fondation Arnold, qui est en cours de déploiement dans 21 juridictions aux États-Unis (Dewan, 2015), utilise 1,5 million d'affaires pénales pour prédire le comportement des défendeurs dans la phase précédant le procès. De même, la Floride utilise des algorithmes d'apprentissage automatique pour fixer le montant des cautions (Eckhouse, 2017). Ces systèmes sont également utilisés pour déterminer les besoins criminogènes des délinquants, qui pourraient être modifiés par un traitement, et pour surveiller les interventions dans les procédures de condamnation (Kehl et Kessler, 2017).
L'étude des biais algorithmiques sort du cadre de ce cours. Les lectaires intéressé·es pourront se référer à Schuilenburg et Peeters, 2021[7].
Conclusion
La surveillance n'est ni l'observation seule ni le contrôle : elle consiste à comprendre et influencer les choix [...] Les pratiques de surveillance obéissent aux impératifs de rentabilité : elles transforment l'information en capital et non en pouvoir. Contrôler, c'est réguler. Surveiller, c'est observer et produire de l'information [...] L'économie de la surveillance est une conception du monde où les individus et leurs choix peuvent être compris comme des procédures marchandes que l'on peut influencer, analyser, mesure à travers le recueil d'informations, c'est-à-dire l'accumulation de données et de sens. À ce titre, production et consommation sont les interactions sociales qui génèrent de l'information et, donc, de la surveillance ( Masutti, 2020[8]).
Consommation et production sont à comprendre au sens large : c'est le cadre marchand dans lequel toutes les actions des personnes sont catégorisées. En d'autres termes, l'économie de la surveillance rationalise tout selon des règles économiques.