Représentation du texte
Impossible d'accéder à la ressource audio ou vidéo à l'adresse :
La ressource n'est plus disponible ou vous n'êtes pas autorisé à y accéder. Veuillez vérifier votre accès puis recharger la vidéo.
Transcription textuelle
Objectif
Découvrir des représentations de données textuelles.
Mise en situation
Lorsqu'on écrit un texte avec un ordinateur, les caractères, à l'instar des autres informations manipulées par la machine, sont représentés par des nombres. Historiquement le premier standard est ASCII qui permet de représenter 128 caractères : les lettres minuscules, majuscules, les chiffres, l'espace, des symboles comme le signe « % »
, et des caractères spéciaux comme le saut de ligne ou la tabulation.
ASCII est un standard américain qui n'inclut pas les caractères d'autres alphabets. Il n'y a pas les caractères accentués européens, ni les caractères arabes, ni les idéogrammes asiatiques par exemple.
Le standard Unicode, largement utilisé aujourd'hui, permet en théorie de représenter plus de 4 milliards de caractères. En pratique, il comporte aujourd'hui plus de 130.000 caractères qui permettent de traiter la quasi-totalité des langues connues.
Fondamental : ASCII : le premier standard pour la représentation du texte
Il y a vite eu une volonté de représenter les textes sous un format numérique à l'arrivée de l'informatisation. En effet, les nombres sont facilement traitables par un ordinateur. Le format ASCII, pour « American Standard Code for Information Interchange », a été créé à cette fin. Celui-ci utilise 7 bits pour représenter chaque caractère. Les caractères représentables en ASCII sont les lettres majuscules et minuscules, les chiffres ainsi que les symboles mathématiques et de ponctuation.
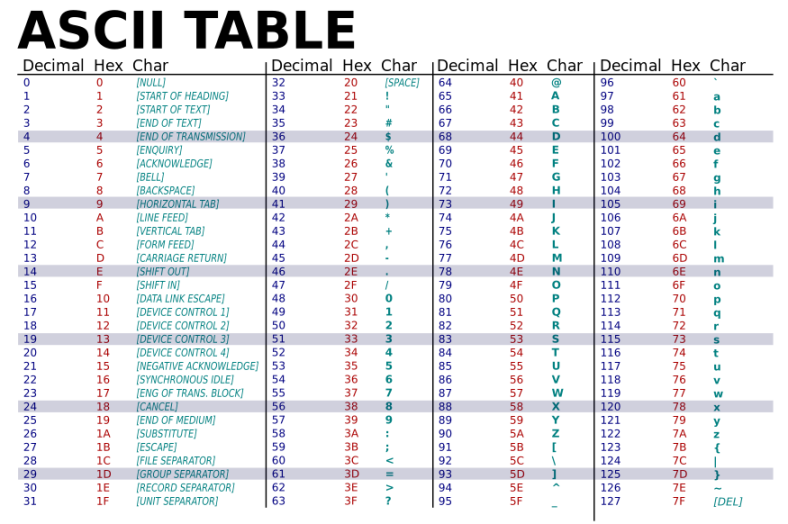
C'est un choix suffisant pour de simples textes en anglais, néanmoins il ne peut pas être utilisé pour les accentuations et les caractères d'autres alphabets.
Remarque : UTF-8, UTF-16 et UTF-32 : des formats d'encodage textuel modernes
Aujourd'hui, dans des efforts d'internationalisation, des formats universels ont été mis en place pour représenter la quasi-intégralité des caractères utilisés dans les langues du monde entier.
Ces formats sont UTF-8, UTF-16 et UTF-32 qui utilisent respectivement 8, 16 et 32 bits pour représenter les caractères. Ceux-ci sont rétro-compatibles avec ASCII dans leur conception. UTF signifie Universal Character Set Transformation Format et ces encodages ont été développés par l'Organisation internationale de normalisation connue sous l'acronyme ISO.
La plupart des émoticônes peuvent ainsi être représentés en UTF-8.
Exemple : Encodage de la lettre A en UTF-8, UTF-16 et UTF-32
A est codé en ASCII par 41 en hexadécimal (ce qui équivaut à 65 en décimal).
UTF-8, UTF-16 et UTF-32 codent A par les 3 codes suivants :
41 (donc comme en ASCII)
FEFF0041
00000041
À retenir
Il existe plusieurs manières de représenter les caractères, appelées encodages.
ASCII fut le premier et laisse aujourd'hui la place à UTF-8, UTF-16 et UTF-32 pour l'internationalisation.
Impossible d'accéder à la ressource audio ou vidéo à l'adresse :
La ressource n'est plus disponible ou vous n'êtes pas autorisé à y accéder. Veuillez vérifier votre accès puis recharger la vidéo.